

デジタル庁2023年度事業 行政での生成AI利活用検証から見えた10の学び (3/3)

デジタル庁のAI担当の大杉直也です。この記事では、業務に必要な情報検索機能に生成AIを活用する方法について考察します。本記事はAI事業者ガイドライン(第1.0版)の分類に従うと、AI提供者に向けた記事であり、情報検索やテキスト生成AIに関する専門的な内容を含みます。
本記事は、「デジタル庁令和5年度事業 行政での生成AI利活用検証の結果報告(以降、報告書とよびます)」から得られた知見を、よりわかりやすく具体的に示すために、「10の学び」の形式にまとめたものです。
その検証ではデジタル庁を中心とした行政職員を対象に、実際に複数種類のテキスト生成AIを取り扱える環境+ユースケースごとの独自開発を含むサポート体制を作り、(1)どの行政業務に対し、(2)どのようにテキスト生成AIを使えば、(3)どのくらい改善効果がありそうか、を調べました。 また、報告書には含まれていなかった個別ヒアリング等による知見も反映させています。
文量が少し多くなってしまったため、全3回の構成で紹介いたします。第1回では10の学びのうち、最初の5つの学びをまとめました。第2回では残りの5つのうち、4つの学びをまとめました。最後の学びは本記事で紹介します。
今回得られたテキスト生成AIの業務活用への10の学びの一覧です。
時間の削減だけでなく品質向上も狙える
業務を工程に分解し、生成AIを使うべきでない箇所を意識する
「書く」だけでなく「読む」も得意
活用用途をチャットインターフェースに限定しない
「業務改善」だけでなく「システム改善」のためにもテキスト生成AIの検証環境は重要
初心者向けにコピペで使える状態が重要
作文に不慣れな人や、一般的な業務知識に乏しい人はテキスト生成AIの恩恵を受けやすい
繰り返し発生し、工程が切り出しやすい業務はテキスト生成AIの恩恵を受けやすい
ソースコードの作成業務はテキスト生成AIの恩恵を受けやすい
情報検索機能は個別具体のニーズに応じた特化開発の余地がある
本記事では最後の10の学びを解説します。
情報検索機能は個別具体のニーズに応じた特化開発の余地がある
テキスト生成AIの求められる用途のひとつには、「知りたい情報の検索、調査」といったものがあります。

「知りたい情報の検索、調査」も大きく分けると、(1)正解がここにあることはわかっているが、それを特定できていない、(2)正解の情報がどこにあるのか目途も立っていない、という2種類があります。
(1)の正解がある場所の目途が立っている場合、テキスト生成AIの知識に頼らずに、その範囲でAIシステム(本記事では、テキスト生成AIだけでなくキーワード検索機能等も含めた用語として扱います)が人間の代わりに探し出すことが目的になります。
(2)の場合はテキスト生成AIの知識だけでは、最新の情報が反映されていなかったり、文字の並びからそれっぽいだけの不正確な情報を返したり(幻覚:ハルシネーションと呼ばれる現象)と課題があるため、Web検索機能と組み合わせて、Web検索結果を引用させながら回答させるといった技術がしばしば用いられます。この両方でテキスト生成AIだけでなく検索機能との組み合わせが重要になってきます。
しかし、このテキスト生成AIと検索機能の組み合わせに絶対の正解は存在せず、どのような組み合わせが適切かは、(1)ユーザーにどのような検索体験を提供したいか、(2)検索結果の品質目標はどの程度か、(3)レスポンスの遅さがどこまで許容可能か、(4)運用コストがどこまで許容可能かといった要件によって変わります。これが本記事の主旨です。
品質とコスト(及びレスポンスタイム)のトレードオフは一般的な話であり、頻繁に議論されていますが、検索体験や特に行政に特化したニーズについてはあまり語られていないため、本記事で詳しく紹介します。

本事業では、デジタル社会推進標準ガイドラインのひとつである「DS-120 デジタル・ガバメント推進標準ガイドライン実践ガイドブック(以降、実践ガイドブックと呼びます)」に基づいた正確な回答を行うAIシステムの構築を検討しました。
このガイドラインは、
デジタル・ガバメント推進のためのサービス・業務改革並びにこれらに伴う政府情報システムの整備及び管理について、プロジェクトを運営する職員の視点に立って実務的なノウハウ、実例、ひな形等を記載した標準ガイドライン参考文書
と位置付けられており、多くの行政職員から参照されます。参照するだけでなく、この内容に関する問い合わせも多く来ているようです。
本事業では、質問者に直接答えを返すAIシステムではなく、質問を受ける担当者の生産性を改善する目的での導入を検討しました。

このAIシステムでは、(1)可能な限りLLM(Large Language Model、テキスト生成AIの中核をなすモデル)への入力に実践ガイドブックの内容を含める手法と、(2)実践ガイドブックを登録した検索エンジンを用意し、その検索結果をLLMへの入力とするアプローチの2種類を試しました。
報告書では、(1)のアプローチをシステムプロンプト、(2)のアプローチをRAGと称しているため、本記事でも以降はその呼称を用います。
細かい補足
(1)システムプロンプトベースのアプローチは当時(2024年2月中旬)の利用可能なLLMで最も受付可能文字数が多いAnthropic社のClaude 2でもすべての内容はおさまらなかったため、事前に実践ガイドブックを章ごとに生成AIで要約したものを用いました。本記事執筆時点(2024年4月末)ではGoogleのGemini Pro 1.5であれば要約しないでも全文をLLMの入力に含めることができます。
(2)RAGベースのアプローチで利用された検索エンジンは汎用的なクラウドサービスをほぼそのまま利用されており、PDFは適当な形で分割され、汎用的な埋め込み表現でのコサイン類似度の一番大きい結果を生成AIへの入力に送るものでした。
テストの実施について
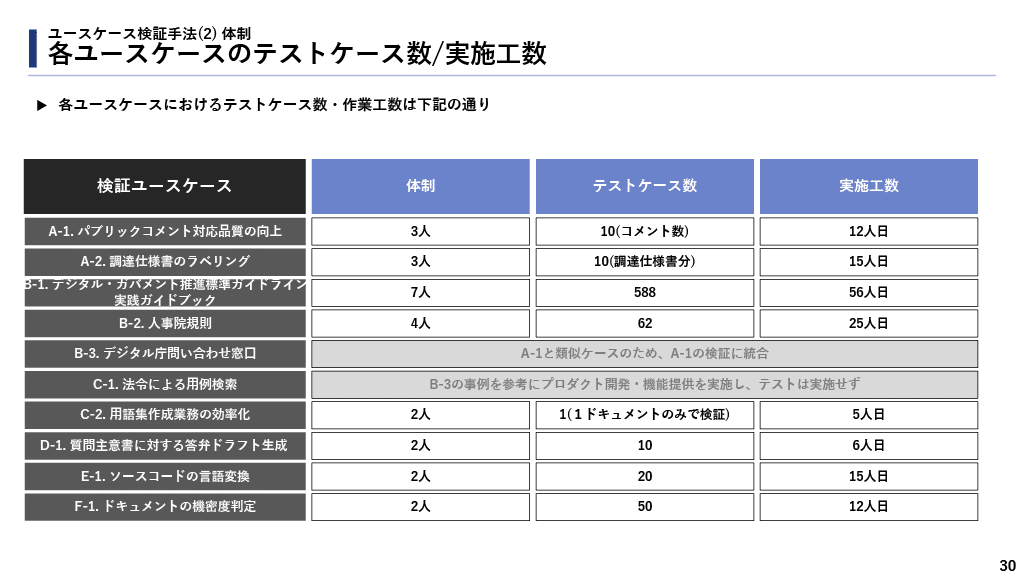
このAIシステムの品質評価を実施するためにテストケースの作成を行いました。テストケースは実践ガイドブックの章ごとにその内容に関連した質問、複数の章にまたがる質問、実践ガイドブックとは関係ない質問をそれぞれ作成しました。テストケースは全部で588問作成され、その具体的な内容はこちらに公開しています。
テストケース一覧

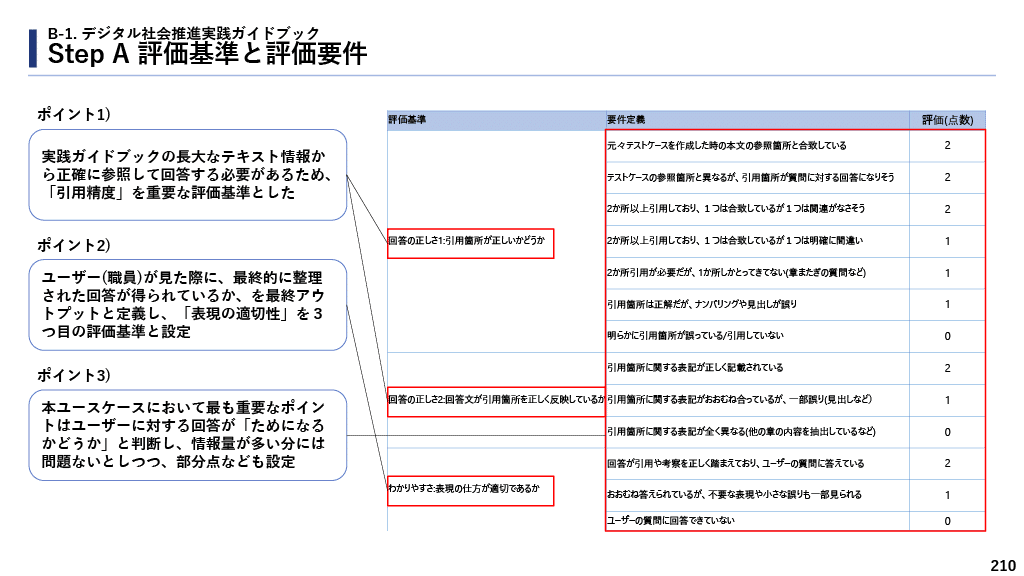
このテストケースの出力は人間の採点者(本事業の委託事業者のヘルプデスク)で評価されました。その際、評価観点の個人間のばらつきを抑えるために、評価観点を明確にしました。
評価観点をこれら3つに分解し、(1)引用箇所が正しいか(回答の正しさ1)、(2)引用内容を正しく反映しているか(回答の正しさ2)、(3)表現の仕方が適切であるか(分かりやすさ)、この中でさらに細かく点数付けをしていきました。これは業界で広く用いられている指標ではなく、この検証のために考案した独自のものになります。
このテストケースと評価観点でシステムプロンプトをベースとしたアプローチのAIシステムを評価した結果、平均得点率は85.3%という数字になりました。これは質問を受けた担当者の業務の参考としては実用的な水準ですが、質問者に直接返却するシステムと考えた場合にはまだ実用化は厳しいと考えました。
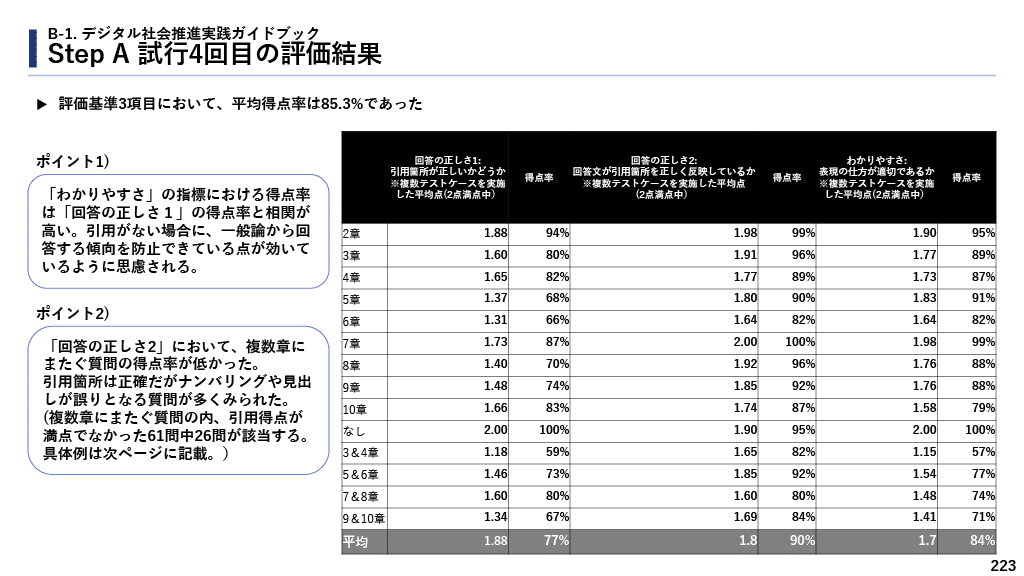
次に、システムプロンプトベースのアプローチで得点率が低かったテストケースでRAGベースのアプローチの得点率を調査しました。RAGベースのアプローチの設計から複数章をまたいだ質問の回答はできないことが自明だったので、単一章のテストケースのみで比較しました。

この結果から、単純なRAGベースのアプローチよりもシステムプロンプトベースのアプローチの方が良い数値であることがわかりました。ただしRAGベースのアプローチでも(1)検索エンジンに登録する際にPDFを意味ある単位(節単位など)に分割する、(2)複数の検索結果をLLMの入力にする、(3)内部の検索アルゴリズムの固有名詞対応や章ごとのタグ付けなどの工夫を行う、などといった改善案がまだまだ考えられます。
この工夫を実施する際に一番のボトルネックになるのは、改善したかを確認するテストです。
今回のユースケースの検証では、プロンプトの試行錯誤もあったとはいえ、全部で56人日のテスト工数がかかりました。この部分においても、テキスト生成AIを使った工数削減が行われなければ、細かい試行錯誤が難しくなるでしょう。
このようなテストで品質評価を行う場合、テキスト生成AIによる品質評価の信頼性や、テストケースや評価基準の妥当性も問題になってくることが予想できます。AIシステムの品質目標の基準に今回のようなテストの導入をし、テスト作成者も評価者もAIシステムの開発事業者の場合、いわば自分が受ける試験問題を自分で作るようなものであり、何らかの客観性をもたせる工夫が必要そうです。
システムプロンプトベースのアプローチはLLMへの入力文が長大になるため、1リクエストあたりの費用が大きくなりすぎる問題があります。今回のシステムプロンプトベースのアプローチの1回あたりのリクエストにかかる平均費用は0.491アメリカドルであり、一般的なWebサービスの検索機能として採用するにはあまりにも高価すぎます。また、レスポンスタイムもかなりかかります。
一方で、RAGベースのアプローチと違って、初期開発の工数は大きく抑えられ、検索エンジンの運用費用もかからないことから、内部利用等の限られた使い方であったら、他の手法と比べて、必ずしも高価すぎる、という結論にはならないです。レスポンスタイムも許容しやすいです。つまりは要件次第で現実的な選択肢になります。
システムプロンプトベースのアプローチの方も、(1)LLMの出力結果をもう一度LLM(他の種類のLLMも含め)で確認させる(2)複数のLLMに同時に問い合わせその結果をLLMで統合させる、等のアプローチにより性能改善が見込めます。このアプローチをとった場合、リクエストあたりの費用やレスポンスタイムは悪化するので、これも品質目標とのトレードオフで考える必要があります。次の事例では、検索結果をさらにLLMで処理する事例を紹介します。
行政特有の特殊な情報検索ニーズについて
次に、行政特有と思われる特殊な情報検索ニーズの紹介をいたします。
行政職員が影響力の大きい作文を行う場合に、かなり特殊な情報検索ニーズを発見しました。最も極端な事例は法令の作成業務です。これは、単語や文章の用法を既存文章のものをできる限り踏襲したいため、用例による情報検索を行いたいというニーズでした。前例主義とも言い換えられます。行政の前例主義と言うと、あまり好意的でない印象を持たれがちですが、この場合の前例主義は非常に合理的です。なぜなら、既存の単語を新しい意味で使った場合、過去の文章作成時に緻密に組み立てられた論理展開を破壊し、文章間の論理的整合性が取れなくなる危険があるからです。そのため、行政職員は重要な作文ほど、過去の用例を知りたいニーズが非常に大きいです。
そこで、本事業の前に、用例による法令検索を生成AIベースで実現可能か、実現した場合にニーズがありそうか、の概念検証を行っていました。
その結果の一部はAI等を利用した法制事務補助の実験結果について (現時点までの実施結果報告)で報告しております。

この概念検証を元に、本事業では用例による法令検索機能が作られました。この検索体験の実現には汎用的なチャットインターフェースではなく、ユーザーに用語と用例を明示的に入力させる検索インターフェースが望ましいと考えられたため、この機能専用の画面が作成されました。


この機能では検索結果をテキスト生成AIで絞り込ませることによって、利用者の利便性を高めています。この仕組みを採用したため(1)最初の検索結果に該当結果が含まれなければならない(再現率の課題)(2)テキスト生成AIの処理での偽陰性リスク(Yesと返すべきものをNoと返す失敗、適合率の課題)がある、といった制約があります。
そのため、「その用語がその用例で使われた先例を網羅的に知りたいケース」では本機能はあまり使えませんが、一方で「その用語がその用例で使われた先例を一例でも知りたいケース」では有用です。実際の業務では一例でも知りたいケースの方が多いようです。
この機能にはまだまだ改良の余地がたくさんあります。再現率の改善案には、検索前により適切な用語を推薦する機能が考えられます。一般的な検索機能の再現率の改善では、辞書による同意語・表記ゆれ・シノニム対応や、埋め込み表現を使った近傍検索等が考えられますが、今回の前例主義的なニーズでは「ユーザーが指定した用語がそのままの形で含まれていること」が非常に重要であるため、これらの方法は採用できません。
そこで、ユーザーが検索する前に「その用語で検索するなら、こちらの用語の方が検索した方が良い」を明示する機能が重要になってきます。情報検索の専門用語でいうとQuery Understandingの要素のSpelling CorrectionやRelated Search Suggestionsが該当します。
適合率の改善案には、テキスト生成AIのプロンプトの改良が考えられます。現在の概念実証のものだと、用例に関する記述がis being treated asやis used as an usecase of が用いられていますが、このどちらが良いかも定かではないです。これは本機能に対するテストケースや評価観点を定められていないため評価不能な状態になっているためです。おそらく最適なプロンプトは、もっと丁寧にコンテキストを説明し、例示をのせたものになると考えられますが、現時点ではプロンプトの改良影響が測定できず、プロンプトの改良に着手できない状態です。改善を実施するためのテストケースや評価観点の整備が次の課題となります。
まとめ
ここまで2種類の情報検索のニーズを見てきました。情報検索のニーズによって、最適な検索体験が変わり、それを実現するユーザーインターフェースや情報の流れの中でのテキスト生成AIの利用方法の最適解が変わることが示せたかと思います。
この情報の流れの中でのテキスト生成AIの利用方法のパターンはRetrieval-Augmented Generation (RAG)の発展形という形でいくつものパターンが提唱されており、近年中にデザインパターンのようにまとめられると予想されます。このパターンのどれを採用するかは回答品質・回答レスポンスタイム・コスト等の目標によって変わってきます。また、後半の例のように特化型のニーズに対してはパターンではなく特化した設計が必要になってくるはずです。その近未来では生成AIを用いた情報検索の導入には
(1) 情報検索ニーズの分析からの要求整理・要件定義。品質目標の整理も入る
(2) 要件定義に応じた設計。既存製品やフレームワーク、パターンが使えるかの判別等
(3) 品質目標に応じたテストケース・評価観点の作成とテストの実施
が重要になってきます。見ての通り、一般的なソフトウェア開発の方法論と大きく変わるわけではなく、考慮すべきコンポーネントにテキスト生成AIが加わるだけです。しかし、テストケースと評価観点に関してはテキスト生成AIを用いない場合のソフトウェア開発よりも恣意性が強くなり、案件固有の対応も多くなることが予想されます。ここの違いが今後どのように開発工程に影響するか、例えばソフトウェアセキュリティでの脆弱性診断のように外部監査機関の需要が高まる等、は引き続き注目していきたいです。
ここまで2023年度事業での検証結果について報告いたしました。デジタル庁では2024年度も政府情報サービスにどのようにテキスト生成AI利活用していくべきかを検証し、積極的に発信していきます。
◆関連するデジタル庁の採用情報は以下のリンクをご覧ください。
◆これまでの「デジタル庁Techブログ」の記事は以下のリンクをご覧ください。
◆デジタル庁の採用に関する情報は以下のリンクをご覧ください。